Advanced LLM Penetration Testing Strategies for Enterprise AI Security and Compliance
Learn How Strategic LLM Pentesting Secures Large Language Models, Mitigates AI Risks, and Ensures Regulatory Compliance in Modern Enterprises
The Need for AI Security in Enterprise
Artificial Intelligence (AI) has rapidly evolved from a futuristic concept to a critical component of modern business strategy. Organizations that hesitate to integrate AI risk falling behind as competitors harness automation, predictive analytics, and real-time intelligence to outperform traditional business models.
According to Forrester, AI-driven automation is projected to reduce operational costs by up to 30% over the next five years, simplifying workflows and enhancing efficiency. Meanwhile, Gartner predicts that by 2026, more than 80% of enterprises will have used generative AI APIs or deployed AI-enabled applications in production environments, making AI not just an asset but a necessity for survival in the digital era.
The imperative is clear: the question is no longer whether organizations should adopt AI, but how swiftly they can do so while ensuring security, compliance, and trust in their AI-driven systems. Embracing AI responsibly and strategically is essential to maintain competitiveness and drive innovation in today's rapidly evolving marketplace.
The Growing Risks of AI Adoption
However, with this rapid adoption comes a growing set of security challenges. Unlike traditional software, Large Language Models (LLMs) dynamically generate responses and make decisions based on complex prompts and data inputs. This behavior introduces a much broader attack surface and increases the likelihood of:
- Adversarial manipulation: Attackers can craft inputs that deceive LLMs into producing unintended or harmful outputs. For instance, research has demonstrated that adversarial prompts can manipulate models to generate malicious content or bypass safety protocols.
- Data leakage: Data leakage through LLMs may inadvertently expose sensitive information present in their training data. A notable case involved Microsoft's Copilot AI, which was manipulated to extract confidential data, highlighting the risk of data leakage through AI-generated responses.
- API vulnerabilities: Exploiting unsecured APIs can allow attackers to misuse or extract underlying AI models. For example, vulnerabilities in AI chatbots have been exploited to perform unauthorized actions, such as sending phishing emails or accessing private data.
- Training data poisoning: Malicious actors can tamper with training datasets to influence AI behavior. An instance of this is the "Nightshade" attack, where poisoned data was used to corrupt the outputs of text-to-image generative models, demonstrating the feasibility of such attacks.
Without AI-specific security measures, organizations risk becoming victims of prompt injection attacks, adversarial threats, and model theft, threats that traditional security strategies aren’t equipped to handle.
The Shift to AI-Driven Security Risks
LLMs are becoming the backbone of automated workflows, customer interactions, and decision-making processes. Their dynamic and adaptive nature makes them both valuable and vulnerable. Unlike static systems, LLMs can respond to evolving prompts, which adversaries can exploit. Security teams must stay ahead of these threats by understanding how LLMs introduce new vulnerabilities into the enterprise.
Emerging AI Security Challenges
- Data Leakage and Insecure Output Handling, LLMs can inadvertently disclose sensitive information present in their training data or through user interactions.
Example: In March 2023, OpenAI's ChatGPT experienced a data breach due to a bug, exposing users' payment information and chat histories. - Adversarial Attacks, Attackers craft deceptive inputs to manipulate the output of AI systems, leading to harmful or misleading responses.
Example: Researchers have demonstrated that slight alterations to input data can cause AI models to misclassify images, such as interpreting a stop sign as a yield sign, posing safety risks in applications like autonomous driving. - Model Theft and API Exploitation, Threat actors can reverse-engineer AI models to steal intellectual property or misuse the service.
Example: OpenAI and Microsoft investigated the Chinese AI company DeepSeek. DeepSeek, a Chinese AI startup, was alleged by OpenAI to have used publicly available APIs to distill their proprietary LLM, raising intellectual property concerns. - Training Data Poisoning, Malicious data can alter the model’s behavior, causing it to make incorrect or biased decisions.
Example: The "Nightshade" technique allows artists to inject poisoned data into their work, causing AI models trained on such data to misinterpret or malfunction, highlighting vulnerabilities in AI training processes.
Why LLM Penetration Testing is Critical for CISOs
As AI adoption accelerates, security leaders must recognize that traditional penetration testing is no longer enough. Unlike conventional security assessments that focus on network and infrastructure vulnerabilities, LLM penetration testing is designed to uncover AI-specific threats, many of which are unique to large language models and their environments.
Hackers are already exploiting AI weaknesses, from prompt injection attacks to model exfiltration and data poisoning. To mitigate these threats, CISOs must proactively implement LLM-specific penetration testing to protect data integrity, model security, and enterprise compliance.
LLM penetration testing addresses key security concerns
- AI Model Integrity – Ensures that AI models are protected from unauthorized modifications, training data poisoning, or bias injection that could manipulate decision-making. (MIT AI Security Research)
- API Security, Strengthens API protections by enforcing rate-limiting, strong authentication, and secure access controls to prevent unauthorized usage and model extraction. (OWASP AI Security Guidelines)
- Adversarial Threat Detection, Identifies vulnerabilities against prompt injection, adversarial machine learning attacks, and content manipulation to prevent exploitation. (Google AI Security Research)
- Regulatory Compliance, Helps enterprises align AI security measures with global compliance standards, such as GDPR, CCPA, and ISO/IEC 42001, reducing legal and financial risks.
Regulatory Considerations
As AI technology advances, regulatory frameworks and security standards are evolving to address AI-specific risks. Security leaders must ensure compliance with these guidelines to protect enterprise AI deployments, mitigate legal risks, and maintain ethical AI governance.
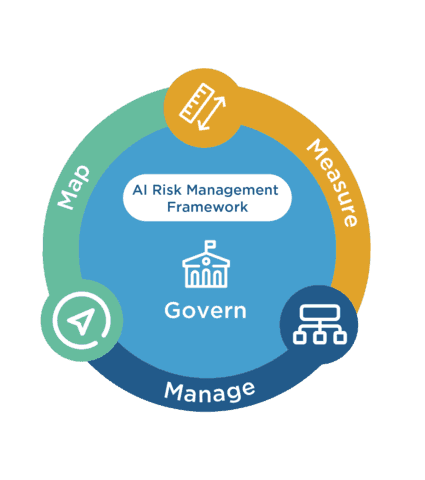
- OWASP Top 10 for LLMs, OWASP Top 10 for LLMs Project identifies the most common vulnerabilities in Large Language Model (LLM) applications and provides mitigation strategies to prevent AI exploitation.
- NIST AI Risk Management Framework – NIST AI RMF complete framework designed to help organizations manage AI risks, focusing on security, transparency, fairness, and accountability
- ISO/IEC 42001 – ISO/IEC 42001 is a first global AI governance standard, ensuring responsible AI deployment and establishing risk management guidelines for enterprises using AI
- GDPR & CCPA – These privacy regulations enforce strict data protection policies for AI-driven data processing, ensuring ethical handling of personal information and user privacy rights.
The Expanding Attack Surface of Large Language Models (LLMs)
LLMs as a New Attack Vector in Enterprise Environments
The adaptability of LLMs is both their greatest strength and their biggest security risk. Unlike static systems, they evolve based on user interactions, opening unprecedented attack vectors for malicious actors.
Key vulnerabilities include:
- Unintended Information Disclosure, LLMs can inadvertently reveal sensitive information through crafted queries. For instance, employees using LLMs to draft reports may unknowingly expose proprietary data. In early 2023, reports emerged of employees using ChatGPT to summarize confidential documents, leading to potential data leaks.
- Unauthorized Decision-Making, Attackers can manipulate AI-driven processes, causing business disruptions. For example, adversaries might inject malicious data into an LLM's training set, leading it to make biased or harmful decisions. This manipulation can degrade model performance, introduce biases, or cause the model to make incorrect predictions.
- Bias and Ethical Concerns, Training data poisoning can introduce harmful biases into AI decisions. For example, if biased data is injected into the training process, the LLM might generate outputs that reflect these biases, leading to unfair or discriminatory decisions. This poses significant risks to organizations and users alike.
Case Studies & Real-World Security Incidents
Synack and Cobalt AI Security have documented multiple incidents where LLM vulnerabilities were exploited in real-world settings:
- AI-Powered Customer Support Bot Breach – In 2023, a financial institution's customer service chatbot was exploited through a prompt injection attack. Attackers crafted inputs that led the chatbot to disclose sensitive customer information, including account details and transaction histories. This incident underscored the vulnerability of AI systems to manipulation via malicious prompts.
- Adversarial Manipulation of Content Moderation Systems, Researchers have demonstrated that AI models can be deceived into producing harmful content by using adversarial inputs. For example, security experts successfully bypassed safety measures of prominent AI chatbots, causing them to generate inappropriate or toxic responses. These findings highlight the susceptibility of AI systems to adversarial attacks that compromise content moderation efforts.
- Model Extraction via API Abuse, A notable case involves the Chinese AI start-up DeepSeek, which allegedly replicated OpenAI's proprietary LLM by analyzing responses from public APIs. OpenAI accused DeepSeek of using a technique called "distillation" to create a competing model, leading to significant intellectual property concerns. This scenario illustrates the risk of model theft through API exploitation.
These threats demonstrate that LLMs require a new approach to security. Enterprises cannot rely on traditional penetration testing and security tools alone. Proactive measures, such as LLM-specific penetration testing, threat modeling, and adversarial resilience strategies, are crucial to safeguarding these AI systems.
LLM Penetration Testing Frameworks & Methodologies for Enterprise Security
Pen-testing Frameworks & Methodologies
AI systems, especially Large Language Models (LLMs), present unique security challenges that traditional security testing methods aren’t equipped to address. Conventional software testing assumes deterministic behavior, where inputs produce predictable outputs. However, AI models generate dynamic responses based on context, making their behavior variable, non-deterministic, and far less predictable. This results in the need for new frameworks and methodologies and upgrades to the existing ones that still have relevance
Why The AI Threat Environment is “Expanding”?
LLMs handle vast amounts of data from multiple sources, including public datasets, APIs, and real-time learning engines like RAG (Retrieval-Augmented Generation). This creates new attack vectors, such as data poisoning, adversarial manipulation, and API exploitation, that traditional security methods cannot fully protect against. The more data sources and integrations an AI system uses, the larger the attack surface becomes.
Another key difference is that AI systems are generative rather than deterministic. In traditional applications, a security test that passes today will continue to pass unless the code is changed. However, an LLM’s behavior evolves over time as it processes new inputs, leading to potential vulnerabilities from model drift and changing outputs.
Why AI-Specific Testing is Critical
AI security risks often stem from data integrity, not just code vulnerabilities. LLMs can be compromised through malicious inputs, biased training data, or inadequate prompt handling. These types of attacks can lead to data leakage, ethical issues, or biased decision-making, which traditional security testing does not adequately address.
Unlike traditional software, AI security requires continuous testing and real-time monitoring. One-time penetration tests and periodic audits are insufficient, as AI models constantly adapt, grow, and learn. Security teams must implement automated threat detection and real-time analysis to stay ahead of evolving threats.
To test AI security effectively, organizations should use AI-powered security tools. These tools can simulate real-world threats, perform adversarial ML testing, and continuously monitor AI behavior for anomalies. Using AI to test AI is essential for identifying vulnerabilities that human-driven security assessments may miss.
LLM Testing Methodologies
Overarching Method
AI Security Methodologies| Phase | Activities |
|---|---|
| Reconnaissance, Identifying AI Endpoints & API Weaknesses |
Map all AI endpoints (APIs, third-party integrations). Check for access control gaps and potential exposure risks. Evaluate input sanitization to detect vulnerabilities in prompt handling. |
| Exploitation, Prompt Injection, Adversarial Testing, and API Fuzzing |
Perform prompt injection to manipulate AI responses. Use adversarial ML techniques (e.g., small text perturbations) to test model robustness. Conduct API fuzzing to reveal weak authentication and insufficient rate-limiting. |
| Model Extraction, Reverse Engineering LLM Architectures & Responses |
Fingerprint outputs to analyze model patterns and potential architecture details. Simulate data inversion attacks to detect sensitive information leaks. Assess IP risks by attempting to replicate the model’s behavior. |
| Testing Fine-Tuning & Poisoning Risks, Manipulating Training Datasets |
Insert malicious data to observe shifts in AI bias. Investigate external data feeds for harmful inputs. Track model drift to detect unintentional or malicious behavioral changes. |
| Remediation & Hardening, Implementing AI Security Controls |
Deploy input validation and sanitization measures. Use content moderation and bias detection tools to maintain responsible AI outputs. Implement real-time monitoring for adversarial attacks and anomalies. |
AI kill chain
- While the Lockheed Martin Cyber Kill Chain provides a strong foundation for traditional application security and can still be applied to certain AI-based scenarios, it has notable limitations for Large Language Model (LLM) security. It does not inherently address factors such as model size and complexity, continuous learning processes, concept drift, and emerging LLM-specific threats (e.g., prompt injection and model poisoning). Although it’s possible to retrofit these issues into the Cyber Kill Chain’s framework, the rapid evolution of attack vectors for LLMs can render such adaptations insufficient on their own.
- To achieve more complete coverage, consider integrating additional frameworks tailored to AI security, such as \S, the OWASP Top 10 for LLMs, and the NIST AI Risk Management Framework (AI RMF).
- A hybrid approach (combining the Cyber Kill Chain with these specialized methodologies) often provides the most resilient defense, but the exact mix should ultimately align with the organization’s unique risk profile and operational needs
Additional Approaches
- Red Teaming: Enlist a dedicated team to simulate consented adversarial attacks. Document vulnerabilities and propose mitigation strategies.
- Adversarial Testing: Follow systematic, pre-established testing methodologies rather than exploratory approaches. Emphasize reproducible results and consistent metrics
- Benchmarking & Evaluation: Compare the model’s security posture against known frameworks and established standards. Use predetermined conditions to identify gaps and track improvements.
Note: Because of the complexity and breadth of the LLM environment, using AI-driven tools for automated and in-depth testing often yields more thorough results than manual methods.
Popular Tools for AI Pen-Testing and Benchmarking
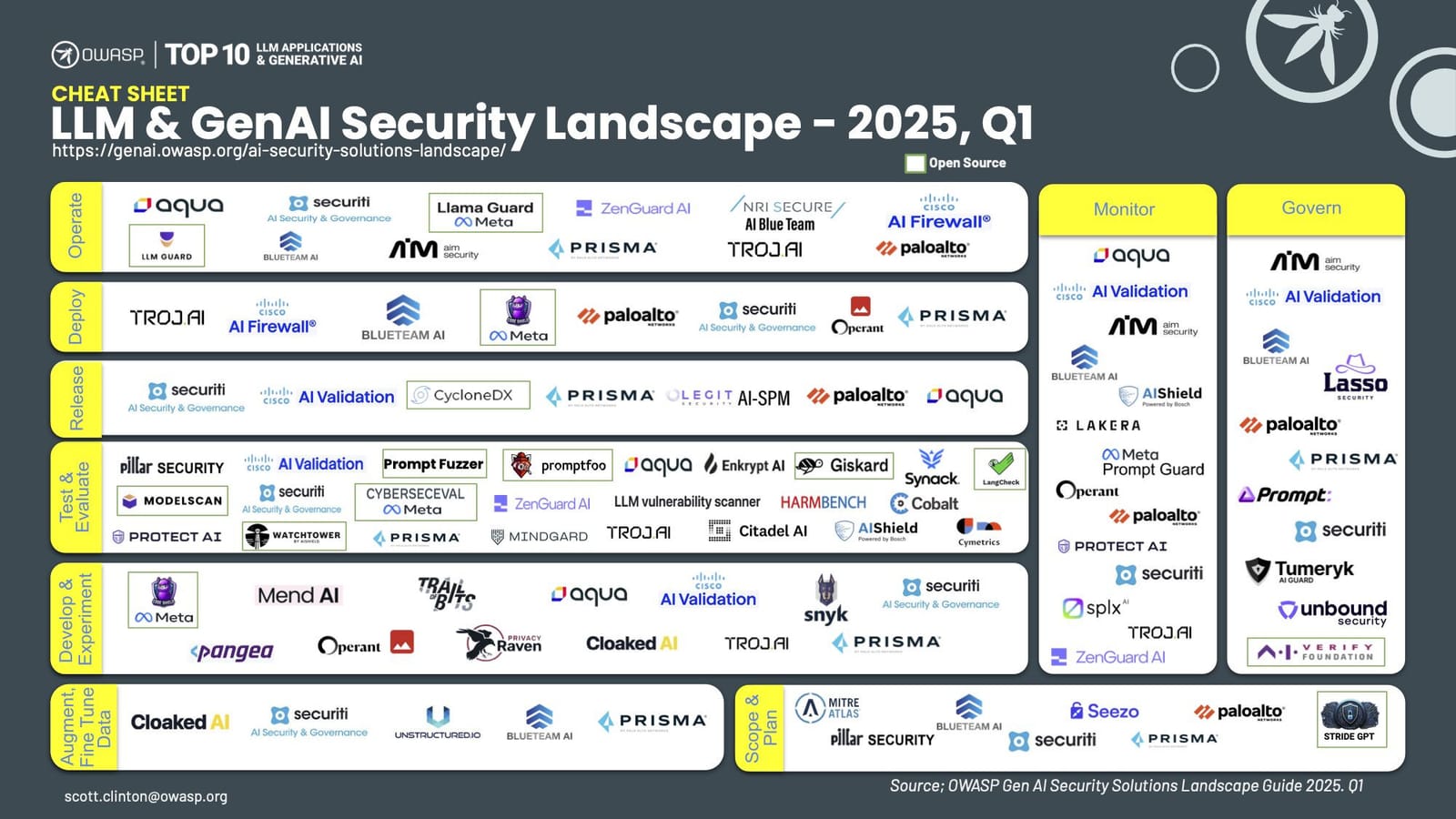
| Company / Tool | Features |
|---|---|
| Cobalt.io |
Offers structured AI penetration testing services. Delivers real-time vulnerability scanning for AI applications. Provides transparent cost models and risk assessments. |
| Synack |
Combines human-led and AI-driven penetration testing. Provides real-time reporting and continuous monitoring of AI vulnerabilities. Actively updates threat intelligence to address emerging risks. |
| Bug crowd |
Harnesses a crowdsourced network of security researchers. Customizable AI-centric programs to discover and address vulnerabilities. Integrates risk scoring for rapid prioritization and remediation. |
| IBM Adversarial Robustness Toolbox (ART) |
Open-source toolkit for generating adversarial examples and defenses. Supports a range of ML frameworks for broad applicability. |
| Microsoft Counterfit |
Automates adversarial testing scenarios specifically for machine learning models. Simplifies common attacks, including evasion and poisoning. |
| Hugging Face Evaluate |
Provides standard metrics for benchmarking and comparing LLM models. Integrates smoothly with Hugging Face’s ecosystem for quick testing. |
| OpenAI Evals |
Framework for creating and running evaluation suites. Facilitates stress-testing LLM performance under varied attack conditions. |
OWASP Top Ten for LLM
Prompt Injection
Attackers add malicious instructions to override the model’s safety features, potentially revealing hidden data or generating harmful content. Mitigation involves filtering and sanitizing user inputs and strictly enforcing system-level rules.
Data Poisoning
Adversaries insert deceptive or biased information into the training data, skewing the model’s outputs. Proper data validation, anomaly detection, and controlled re-training are essential to maintain model integrity.
Data Leakage (Model Inversion)
Carefully crafted queries can prompt the model to disclose sensitive information from its training data. Techniques like differential privacy, query monitoring, and output filtering help mitigate these leaks.
Model Theft (Extraction)
Attackers replicate the model’s functionality by analyzing numerous responses. Strong API access controls, rate limiting, and response obfuscation can reduce the risk of unauthorized duplication.
Adversarial Inputs
Slightly modified inputs can confuse the model into producing incorrect or malicious outputs. Adversarial training, resilient input preprocessing, and anomaly detection help maintain reliable performance.
Unauthorized Access & API Abuse
Insufficient API security allows attackers to misuse the model for spam or phishing. Implementing authentication, rate limiting, and continuous monitoring prevents unauthorized usage.
Bias and Ethical Risks
The model might reflect biases in its training data, leading to unfair or discriminatory outputs. Regular bias evaluations, diverse training sets, and ongoing oversight promote ethical AI behavior.
Poor Content Filtering
Inadequate filters may let the model produce offensive or harmful content. Enhanced moderation systems and post-processing checks ensure compliance with content standards.
Denial of Service (DoS)
Excessive requests can overwhelm system resources, causing service disruptions. Rate limiting, load balancing, and scalable infrastructure protect against DoS attacks.
Intellectual Property Risks
The model may inadvertently reproduce copyrighted or sensitive information from its training data. Output reviews, watermarking, and strict content controls help prevent unauthorized disclosures.
Compliance & Risk Management for AI Security Leaders
Compliance Frameworks
Adopt established standards to ensure your AI systems meet global requirements and demonstrate a strong commitment to security. These include:
- OWASP AI Security Guidelines for best practices in securing AI and machine learning applications.
- ISO/IEC 42001 to address AI-specific security standards
- GDPR (General Data Protection Regulation) for data privacy in the EU
- CCPA(California Consumer Privacy Act) for consumer data privacy in the US
- NIST AI Risk Management Framework for thorough guidelines on identifying and managing AI-related risks.
Key Focus Areas
Protect personal and sensitive information through secure data handling and strong access controls. Communicate clearly about how AI models make decisions, how data is used, and what measures are in place to safeguard information. Address potential biases, ensure fairness indecision-making, and continually assess the societal impact of AI deployments.
Enterprise Governance
Develop clear, organization-wide policies that safeguard data integrity and privacy. These policies form the foundation of an effective security strategy, guiding everything from technology implementation to employee training.
Security Measures
Implement strict access controls, encrypt data both at rest and in transit, and conduct regular security audits. These steps help you quickly identify vulnerabilities and maintain confidentiality, integrity, and availability of critical systems.
Zero Trust Model
Operate under the principle of never assuming trust. Continuously verify user identities, monitor network activity, and segment resources to minimize damage if a breach occurs.
Incident Response
Create simplified workflows for detecting, containing, and resolving security incidents. Include post-incident analysis to identify root causes and improve future defenses.
Outcome
By following these practices, you can strengthen your AI deployments, maintain compliance with international regulations, and protect your organization’s most valuable assets.
The Future of AI Security & Next Steps for CISOs and Security Leaders
Emerging Threats
Cyberattacks are becoming more complex, with AI tools enabling rapid and sophisticated breaches. Traditional security measures are no longer enough to handle these new challenges.
- Organizations must adopt AI-specific security frameworks like OWASP AI Security Guidelines and NIST AI Risk Management Framework to ensure that their AI systems remain secure and compliant with industry standards. These frameworks offer structured approaches to managing AI risks, from governance to technical controls.
- Automation is key to effective AI security. AI-driven penetration testing and threat detection solutions can monitor and adapt to new threats in real time. This approach allows security teams to identify and mitigate vulnerabilities as they emerge, rather than relying solely on reactive measures
- Beyond technical defenses, organizations should enhance governance, risk management, and compliance processes for AI deployments. This includes establishing strong AI security policies, conducting regular risk assessments, and ensuring that AI models adhere to ethical guidelines. By taking these proactive measures, enterprises can secure their AI systems against a rapidly evolving threat environment.
Adapting to Change
Security leaders must update their strategies. This means using AI-powered tools for continuous monitoring and quickly detecting any unusual activity. A Zero Trust approach, where every access request is verified, is key to keeping systems secure.
Looking Ahead
The path forward involves regular security checks and updates to find and fix weaknesses before they are exploited. Investing in advanced security technologies and working with industry experts will help build a strong defense against future threats.
Actionable Next Steps
Integrate AI Security into Enterprise Risk Management
Begin by aligning your security strategy with recognized frameworks such as NIST, OWASP, ISO/IEC 42001, GDPR, and CCPA. This integration ensures that AI security is an integral part of your overall risk management approach.
Regular Security Assessments
Implement a schedule for periodic security reviews. This includes conducting AI security assessments, red teaming exercises, and penetration testing on large language models to continuously evaluate and strengthen your defenses.
Invest and Collaborate
Invest in advanced AI security tools and provide ongoing training for your staff. Collaboration with industry experts and adherence to best practices are crucial to staying ahead of evolving risks and adapting to new threats.
Conclusion
A proactive, automated, and complete AI security strategy is essential in today’s rapidly evolving threat environment. Security leaders must continuously adapt and work together to safeguard enterprise assets and ensure strong protection against emerging challenges.